The Open-AI CLIP text-to-image generator
https://ml.berkeley.edu/blog/posts/clip-art/
(…)
These models have so much creative power: just input some words and the system does its best to render them in its own uncanny, abstract style. It’s really fun and surprising to play with: I never really know what’s going to come out; it might be a trippy pseudo-realistic landscape or something more abstract and minimal.
And despite the fact that the model does most of the work in actually generating the image, I still feel creative – I feel like an artist – when working with these models. There’s a real element of creativity to figuring out what to prompt the model for. The natural language input is a total open sandbox, and if you can weild words to the model’s liking, you can create almost anything.
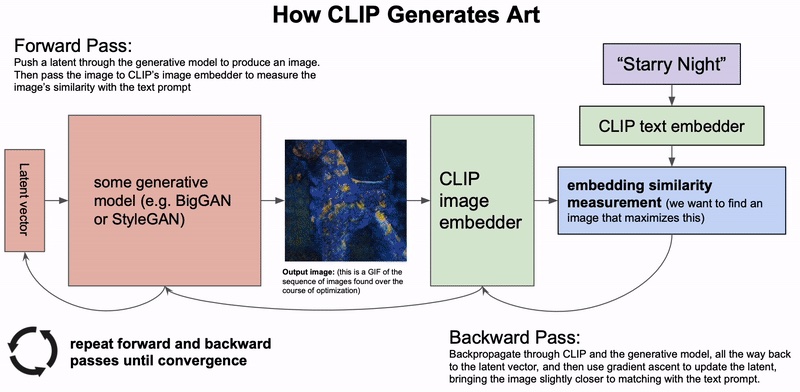
In concept, this idea of generating images from a text description is incredibly similar to Open-AI’s DALL-E model (if you’ve seen my previous blog posts, I covered both the technical inner workings and philosophical ideas behind DALL-E in great detail). But in fact, the method here is quite different. DALL-E is trained end-to-end for the sole purpose of producing high quality images directly from language, whereas this CLIP method is more like a beautifully hacked together trick for using language to steer existing unconditional image generating models….

Relevant Twitter Accounts
(these are all twitter accounts that frequently post art generated with CLIP)
@ak92501
@arankomatsuzaki
@RiversHaveWings
@advadnoun
@eps696
@quasimondo
@M_PF
@hollyherndon
@matdryhurst
@erocdrahs
@erinbeess
@ganbrood
@92C8301A
@bokar_n
@genekogan
@danielrussruss
@kialuy
@jbusted1
@BoneAmputee
@eyaler